
 There has been a lot of chatter lately about the Lync 2013 Stress tool particularly since Microsoft just released a new guide about this tool. The guide is very useful as figuring out the tool on your own is….challenging.
There has been a lot of chatter lately about the Lync 2013 Stress tool particularly since Microsoft just released a new guide about this tool. The guide is very useful as figuring out the tool on your own is….challenging.
In short, the tool works by simulating a heavy load of traffic against your Lync environment. If your servers can handle the load you have defined then you can be fairly confident that your installation is ready for production.
However, there is a big caveat that needs to be explained before you launch this against your Lync servers that sit in any semblance of a production environment. By “any semblance of a production environment” I mean the Active Directory domain that houses your production or pre-production Lync 2013 servers, any other Lync installs that share the same Lync Organization as the pool you want to test, and anything else that might get pegged harder than usual due to this testing such as network bandwidth or firewalls.
In section 5.1 of the guide, Microsoft even mentions the following:
To stress test Lync Server using LSS, it is best to use an isolated lab environment. The stress testing lab needs to include:
-
Active Directory Domain Services domain controllers
-
Active Directory Certificate Services root certification authority
So if MIcrosoft says you should only use this in a lab environment, begin to ask yourself what is the point of testing lab servers? Well….there isn’t much of a point unless you build an exact duplicate in your lab as to what you will put into production. Depending on the size of your environment, this could be a very sizable investment. (It’s not unheard of to have over 30 Lync-related servers in a single pool. Plan on deploying more than 1 pool in a paired-pool config and your lab will get really large (and expensive) though this tool doesn’t stress test every component).
Alternately, you could bring up your entire Lync environment in a Lab domain, stress test it, then uninstall everything (bootstrapper.exe /scorch) and re-install it into production. Assuming you do everything exactly correct then you will at least have a decent idea that your moving-to-production hardware can handle your anticipated load. But that is an awful lot of work to build your environment twice just to get some metrics.
So then what’s the big deal with just running this in production? Why does Microsoft warn against it?
The guide mentions that you need to build client machines to launch the tests. Each client machine can handle no more than 4500 simulated endpoints (with Multiple Points of Presence (MPOP), it goes up to 6,300 but for the purposes of this article, the focus is on the 4,500 endpoints). Each endpoint is actually a user created in your Active Directory environment and each one of these users will be Lync enabled. What happens when you Lync enable a few thousand or tens of thousands Lync users? You need to regenerate the Lync Address Book and push it out to all of your users.
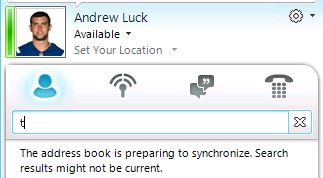
This is exactly what you don’t want your users seeing just because you are testing.
If you are in a small environment then maybe this isn’t a problem. But if you are geographically dispersed and/or your users have limited bandwidth then you can start seeing how there might be issues by throwing abnormally large address books around your network. And if you didn’t think ahead and name your thousands of test users something like ZZZZZZ_LyncUserX then you will have a few thousand new “users” buried smack in the middle of your Lync Address book.
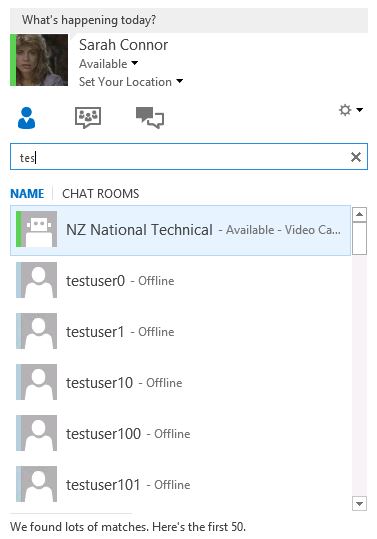
Look at all of those accounts clogging up the address book.
When you remove all of these users a new Address Book will need to be generated and pushed too.
Depending on how robust your AD infrastructure is, do you think your network can handle several thousand users all logging in over a short period of time? Sure you can set the tool to log in users at a rate of one per second but what will this do to any security logging or auditing software you might have in production?
The testing tool can also create a bunch of conference directories that you will have to manually clean up afterwards.
So what should you do instead? Well ask yourself this: What are you really trying to test? The ability of Lync to handle thousands of connections or the ability of your servers to support thousands of connections to Lync? Because quite honestly, I trust Microsoft to make Lync scaleable to handle the maximum load you are looking to run. But where the bottlenecks come is in in your server infrastructure. Is your SQL Server properly scaled? Do you have enough bandwidth between servers or is your switch overrun and dropping packets?
Microsoft has released a Key Health Indicators document that works with Windows Performance Monitor to collect the key metrics you need to make sure that your servers running Lync are running well. You can download a script to create these counters in Performance Monitor. They are part of the Network Planning, Monitoring, and Troubleshooting with Lync Server document. Just run the PowerShell script and it will create a set of Key Health Indicators for you to monitor.
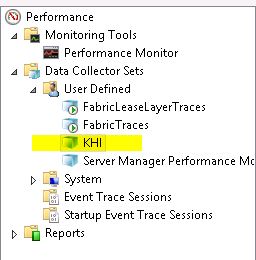
The script creates a Lync-specific KHI collector set within Performance Monitor for you.
Now run the KHI collector set for a few days with no one using the servers. This will create your baseline metrics. Now, begin adding or migrating your users to the Lync 2013 servers. Every week run the KHI metrics and see if you notice any unusual spikes. If so, investigate them as these could be pointing out potential bottlenecks such as disk that is too slow or not enough CPU resources.
Using this method will actually let you monitor your environment and let you know if it is handling the actual stress of your deployment and not a theoretical stress in your lab.
Now, how could Microsoft improve the stress tool? Well, create 1 or 10 or 100 users and have them log in 4000 or 400 or 40 times. The tool allows you to have each user log in multiple times but only up to a “100% ratio”. This means if you have 1000 test users you can have up to 2000 sessions with multiple logins (MPOP). However if you need to stress an environment that would need up to 30,000 endpoints you still need to create 15,000 test users.
So to answer the question that is asked in the title of this article: Is the Lync Stress Tool worthless? My answer is that, unless you are in a small deployment or you are really digging deep into Lync architecture, it is basically worthless. Instead, proactively monitor your Lync servers as you would any other production server and should any issues pop up you will be prepared to handle them before they become catastrophic.
2 pings
[…] few weeks ago I wrote a post basically saying that the Lync Stress Tool was worthless. In it I said you should really monitor the progress of your Lync deployment using Performance […]
[…] few weeks ago I wrote a post basically saying that the Lync Stress Tool was worthless. In it I said you should really monitor the progress of your Lync deployment using Performance […]